- Research
- Open access
- Published:
Path classification by stochastic linear recurrent neural networks
Advances in Continuous and Discrete Models volume 2022, Article number: 13 (2022)
Abstract
We investigate the functioning of a classifying biological neural network from the perspective of statistical learning theory, modelled, in a simplified setting, as a continuous-time stochastic recurrent neural network (RNN) with the identity activation function. In the purely stochastic (robust) regime, we give a generalisation error bound that holds with high probability, thus showing that the empirical risk minimiser is the best-in-class hypothesis. We show that RNNs retain a partial signature of the paths they are fed as the unique information exploited for training and classification tasks. We argue that these RNNs are easy to train and robust and support these observations with numerical experiments on both synthetic and real data. We also show a trade-off phenomenon between accuracy and robustness.
1 Introduction
Recurrent neural networks (RNNs) constitute the simplest machine learning paradigm that is able to handle variable-length data sequences while tracking long-term dependencies and taking into account the temporal order of the received information. These data streams appear naturally in many fields such as (audio or video) signal processing or financial data. The RNN architecture is inspired from biological neural networks where both recurrent connectivity and stochasticity in the temporal dynamics are ubiquitous. Despite the empirical success of RNNs and their many variants (long short-term memory networks (LSTMs), gated recurrent units (GRUs), etc.), several fundamental mathematical questions related to the functioning of these networks remain open:
-
What is the exact type of information that an RNN learns from the input sequences?
-
Training artificial RNNs with classical methods like gradient descent suffers from fundamental problems such as instability, non-convergence, exploding gradient errors [10] and plateauing [27]. On the other hand, biological networks seem to be robust and easy to train. How does stochasticity contribute in regard to this?
-
What is the amount of data needed for such a network to achieve a small estimation error with high probability?
In the current paper, we set out to answer these questions by modelling a biological neural network as a continuous-time (stochastic) RNN with a randomly chosen connectivity matrix and an identity activation function in view of classifying data streams (in this case, time-dependent paths). Let us say a few words about each of our three working assumptions:
-
The continuous-time dynamics are a generalisation of the classical discrete-time dynamics frequently encountered in the literature [14]. The latter can be seen as an Euler discretisation of the former as the data stream is sampled at shorter time intervals. Working with continuous-time dynamics provides us with a richer mathematical toolbox, while still being applicable to the discrete-time case and keeping key features and issues of such systems such as the dependence on the whole data sequence and its order.
-
Randomly generating the connectivity matrix of an RNN is the cornerstone of reservoir computing [20, 31]. This paradigm is based on the idea that universal approximation properties can be achieved for several dynamical systems without the need to optimise all parameters and has shown exceptional performances in a variety of tasks. This working assumption also has the benefit of simplifying the training process (as will be clear from the formulas in this paper, optimising over this matrix is computationally heavy, even in the linear case). This will consist in our case in finding a pre-processing projection vector and the parameters of a read-out map. This simplicity can be practically exploited, for instance to deploy the same network to deal with several tasks (i.e. multi-tasking) without the need for heavy retraining or storing a large number of parameters, in a fashion that is reminiscent of biological networks. Compared to the existing literature (e.g. [9]), we included the pre-processing map (input projection vector) as a tunable parameter in order to increase the performance compared to a classical reservoir computer.
-
We choose to work with identity activation functions in order to build the intuition as to the answer to the questions above. In this case, we obtain precise formulas. We aim to generalise the results of this study to the non-linear case in a later study.
Before setting out our roadmap, let us note for the sake of completeness that there exists a number of ways in which one may avoid altogether recurrent architectures in order to handle data streams and use instead a feed-forward network, which is a more studied and understood paradigm. These are usually based on the transformation of paths into fixed-length vectors that can then be fed to the feed-forward structure. In particular, we cite the Independent Component Analysis [17, 19, 34], the signature methods [15, 21, 26] and the PCA-type dimension reduction introduced in [3]. However, these methods work best when the whole signal is processed (which may be computationally heavy) before being fed to the network, while RNNs are able to work with these signals in a continuous manner as they come, rendering them more suitable to real-time situations. As to the approximation properties of these recurrent architectures, there are several studies that suggest that such properties may also hold for the path-classification problem treated in this paper, although a precise statement in the stochastic case, which is of interest to us, is still missing. For example, rigorous results providing the approximation properties of (discrete-time) RNNs with a randomly generated connectivity matrix can be found in [13]. In [12], it is shown that every continuous path can be approximated (in the uniform convergence norm) as the outcome of an RNN with a suitable activation function, while, more recently in [27], the authors show that an RNN with the identity activation function can approximate any functional on a path space provided it is continuous, linear, regular and time-homogeneous.
We will approach the problem of the binary classification of continuous-time paths with RNNs in the presence of noise from the point of view of statistical learning theory. After introducing the necessary mathematical notation and the learning setup (model, loss function, etc.) in Sect. 2, we will give a generalisation error bound that holds with high probability in Sect. 3. The uniform bound that we derive controls the difference between the risk of an hypothesis and its empirical counterpart and answers practical questions concerning the size of the sample and the bounds on the pre-processing and read-out maps needed to achieve a certain accuracy. Consequently, minimising the empirical risk achieves agnostic PAC learnability and gives guarantees on the ability of the empirical risk minimiser to generalise to unseen data. Section 4 looks in more detail at the empirical risk-minimisation (ERM) procedure:
-
we compare its output to that of the popular Support Vector Machine (SVM) considered for example in [33];
-
argue heuristically that noise, which is a natural assumption in modelling biological neural networks, provides stability and robustness against different types of perturbations to the dataset;
-
show rigorously that in the linear case, the RNN retains a “partial signature” of the time-lifted input signal as global information about said signal. The empirical risk is a function of the tunable parameters of the model and the partial signatures of the training data.
Finally, we look into the numerical minimisation of the empirical risk using gradient descent in Sect. 5. With the explicit formulas we obtain, the global effect through time of the tunable parameters on the loss function is taken into account and we do not need some sort of unrolling of the network to apply back-propagation through time. The experiments are performed using the Japanese vowels dataset and classes of trigonometric polynomials.
2 The learning setup
2.1 The recurrent network input–output map
Let r, n and d be integers. The input and the hidden state of the RNN are modelled, respectively, as r- and n-dimensional time-dependent continuous paths x and y. Given a filtered probability space \((\Omega ,\mathcal{A}, (\mathcal{F}_{t})_{0 \leq t \leq T},\mathbb{P})\), a simple continuous-time model describing the time evolution of input–output dynamics is given by the following stochastic differential equation (SDE) (which can be seen as a stochastic version of the one in [37])
with initial condition taken to be \(y(0)=0\). Here, \(u\in \mathcal{L}(\mathbb{R}^{r}, \mathbb{R}^{n})\) is a linear pre-processing map (identified as a matrix in \(\mathbb{R}^{n\times r}\)), \(W\in \mathbb{R}^{n\times n}\) is the network matrix that models the connection strength between neurons, ϕ is an activation function (applied element-wise) and \(\Sigma \in \mathbb{R}^{n\times d}\) is a matrix (which we will call the noise matrix) describing the random effect of a d-dimensional Brownian noise B. In this paper, we will consider the linear case when ϕ is the identity function. The more interesting case where ϕ is non-linear will be the subject of a future study.
Given a path x, we will denote by \(y(T,x)\) (or \(y_{u}(T,x)\) to emphasise the dependence on the pre-processing map u) the terminal value (i.e. at time T) of the solution to equation (1). A readout map h is then combined with the final hidden state of the neural network to produce a prediction \(v=h(y(T,x))\) (Fig. 1). In our case, h will be a labelling function, and more specifically, a hyperplane classifier.

A sketch of the recurrent learning architecture
Given a training set of labelled inputs, we aim to train this network by changing the values of the parameters in order to increase the accuracy of future predictions (in a sense to be made clear in the following subsections). In the classical framework of reservoir computing, the network’s tunable parameter is the hyperplane h, while the connectivity matrix W and the pre-processing map u are generated randomly. In our case, we aim to increase the performance by considering u to be a tunable parameter to be optimised according to the learning task at hand.
2.2 Hypothesis class and read-out maps
As we have alluded to above, our global hypothesis class \(\mathcal{H}\) comprises of maps that can be written as the composition of the reservoir-solution map \(y_{u}(T,\cdot)\) and a read-out map h chosen from a read-out hypothesis class \(\mathcal{H}^{*}\). As the read-out map h will be applied to the random vector \(y_{u}(T,x)\), we can think of the hypothesis class \(\mathcal{H}\) as a class of random learners
where \(\mathcal{X}\) denotes the space of input paths and \(\mathcal{V}\) the target set of outputs; for example the labels \(\{-1,+1\}\) as will be in our case. If one identifies random variables and their probability distributions, then one may think of the result of the learners applied to an input x as probability distributions instead of a single label. In our very simple setting, this translates into thinking of the hypothesis H as a regression function \(x \longmapsto \mathbb{P}(H(x)=1)\in [0,1]\). This discussion fits into the framework of probabilistic binary classification, or in the wider one of probabilistic supervised learning, as introduced in [16]. However, let us emphasise the fundamental difference that in our case we label inputs based on one realisation of the hypothesis rather than produce a probability distribution on the space of labels.
In the current work, and in line with most common practices, we will take the read-out hypothesis class \(\mathcal{H}^{*}\) to be the class of hyperplane classifiers. We will adopt the following notations:
Notation 2.1
-
(1)
For \(\omega \in \mathbb{R}^{n}\) and \(b\in \mathbb{R}\), we denote by \(h_{\omega ,b}\) the hyperplane classifier with normal direction \(\omega \in \mathbb{R}^{n}\) and shift b
$$ h_{\omega ,b}(y)=\operatorname{sign} \bigl( \langle y, \omega \rangle +b \bigr) \in \{-1,+1\}, \quad \text{for all } y\in \mathbb{R}^{n}, $$with the convention \(\operatorname{sign}(0)=1\).
-
(2)
If \(u\in \mathbb{R}^{n\times r}\), \(H_{u,\omega ,b}\) denotes the global classifier of the stochastic RNN with pre-processing map u
$$ H_{u,\omega ,b}(x)=h_{\omega ,b} \bigl(y_{u}(T,x) \bigr),\quad \text{for all } x \in \mathcal{X}. $$
2.3 Loss functions and associated risk
The goal of supervised learning is to maximise the ability, with high probability and measured against a loss function, of the predicted outputs to generalise to unseen data. As our learner is generating a random variable instead of a deterministic label, we need to consider loss functions of the type \(l: \mathcal{V}^{\Omega } \times \mathcal{V} \to \mathbb{R}_{+}\). Given a classical loss function \(\tilde{l}: \mathcal{V}\times \mathcal{V} \to \mathbb{R}_{+}\) (e.g. the square loss or the binary loss), we may construct loss functions suitable to our framework in two ways, amongst others. The first way is by defining the loss function l to be a statistic of the random variable \(\omega \mapsto \tilde{l}(\tilde{v}(\omega ),v)\), for example
For a fixed input and label, the sole source of randomness in our example is the d-dimensional Brownian motion B with respect to which we will take the expectation. An explicit example would be the binary loss function \(\tilde{l} (\tilde{v},v)=\mathbf{1}_{\tilde{v}\neq v}\) to which we associate the loss \(l(\tilde{v},v)=\mathbb{P}(\tilde{v}\neq v)\). This is the loss function that we will consider in our case. We choose this loss function as it is simpler to analyse than other popular types of losses (square loss, hinge loss, etc.) while involving similar key quantities (the Gaussian cumulative distribution function, as will be seen later) in the classification process and risk minimisation.
A second type of loss function can be obtained by defining a statistical functional \(\Psi : \mathcal{V}^{\Omega } \to \mathcal{V}\) (here \(\mathcal{V}\) can be understood in a broader sense, for example \(\mathbb{R}\), instead of the labels \(\{-1,+1\}\)), then define \(l(\tilde{v},v)=\tilde{l}(\Psi (\tilde{v}), v)\). This type of loss function depends on the distribution produced by the hypothesis rather than on its single realisations and defines therefore a probabilistic loss function in the sense of [16]. An instance of such type would be to take \(\Psi =\mathbb{E}\) and the square loss \(\tilde{l} (\tilde{v},v)=|\tilde{v}-v|^{2}\) to obtain \(l(\tilde{v},v)=|\mathbb{E}\tilde{v}- v|^{2}\).
The generalisation error (also called risk) of an hypothesis \(H\in \mathcal{H}\) associated to a loss function l is then classically given by \(R(H)=\mathbb{E}_{(x,v)}l(H(x),v)\), where the expectation is taken with respect to the (unknown) distribution according to which an input and its label \((x,v)\) are generated. One usually interprets the generalisation error as the ability of the learned hypothesis to generalise well for unseen data, assuming it is sampled according to the same unknown distribution that generated the training sample. As no assumptions are made in regard to the distribution of the data, the generalisation error remains unknown and thus its minimisation, as such, impossible. Instead, one classically aims to minimise its empirical counterpart based on a training sample \((X,V)=\{(x_{i},v_{i})\}_{i=1}^{m}\)
Obviously, one also needs to provide theoretical arguments justifying the use of the empirical error instead of the generalised one. These often come in the form of a concentration inequality. We will recall such an argument using the notion of Rademacher complexity in a subsequent subsection.
If we denote by \(\overline{\mathcal{H}}\) the set of all measurable hypotheses, we can then decompose the difference between the true risk of an hypothesis \(H\in \mathcal{H}\) and the smallest possible risk in the following manner:
On the one hand, the estimation error \(E_{\mathrm{est}}\) depends on the ability to solve the problem of minimising the risk over the chosen hypotheses class \(\mathcal{H}\). Intuitively, this problem becomes more difficult with larger classes of hypotheses. In many situations where the concentration inequalities mentioned above apply, one obtains quantitative guarantees on how small the estimation error \(E_{\mathrm{est}}\) can be made in the case of an empirical risk minimiser
On the other hand, the approximation error \(E_{\mathrm{app}}\) depends on how accurately the hypotheses in \(\mathcal{H}\) can approximate any measurable hypothesis.
3 Generalisation error bounds
3.1 Solution to the SDE
In our simplified case of the identity function as an activation function, and similarly to an Ornstein–Uhlenbeck process, the solution to the SDE (1) is explicitly given by
Notation 3.1
For convenience, we will write \(W_{0}=W-I\).
The final hidden state \(y(T,x)\) is then a Gaussian random vector with mean and covariance matrix given by
Notation 3.2
For the rest of this paper, we will denote
Remark 3.3
Note that the covariance matrix A is independent of the tunable parameters u, ω and b and the input signals. As will be seen later, this is a key property of this algorithm.
It is also interesting to note that in this linear case, the hidden states of different inputs have similar distributions (Gaussian) differing only by their means. Loosely speaking, the role of the parameter u will then be to separate as much as possible the data \(x_{i}\) according to their labels \(v_{i}\)s through their processed weighted averages \(\nu _{x_{i},u}\), while the covariance matrix A quantifies by how much the hidden states are likely to deviate from their means. As in [33], one may be tempted to apply traditional separating algorithms such as soft SVM as a classification technique. However, we follow here a strategy dictated by the risk minimisation and the learning guarantees given by the generalisation error bounds that we will obtain. We will compare these two techniques in a subsequent subsection.
3.2 Empirical risk for the binary loss
As stated in Sect. 2.3, we consider the case of the binary loss function. We will denote by l̃ the classical binary loss function \((\tilde{v},v)\mapsto \mathbf{1}_{\tilde{v} \neq v}\), while l denotes its counterpart associated with random labels (assuming measurability)
We will give first the exact formula of the loss in the pure stochastic regime, which shows the smoothing effect of the noise on the binary loss function. For a lighter notation, we will sometimes avoid making the dependence on other variables explicit. For example, we may write y instead of \(y_{u}(T,x)\).
Proposition 3.4
Let \((x,v)\in \mathcal{X}\times \{-1,1\}\), \(u\in \mathbb{R}^{n\times r}\), \(\omega \in \mathbb{R}^{n}\) and \(b\in \mathbb{R}\). If \(\omega \notin \operatorname{Ker}(A)\), then
where Φ denotes the standard Gaussian cumulative distribution function (CDF).
Proof
First, note that
and that this inequality is not an identity if and only if \(v=1\) and \(\langle y, \omega \rangle +b=0\) (because of the convention on the sign of 0). Next, recall that \(\langle y, \omega \rangle +b\) is a Gaussian random variable
We assume that \(\omega \notin \operatorname{Ker}(A)\). Then, \(\langle y, \omega \rangle +b\) is a non-trivial Gaussian random variable (and \(\mathbb{P} ( \langle y, \omega \rangle +b=0 )=0\)). Consequently
which completes the proof. □
Remark 3.5
Note that if \(\omega \notin \operatorname{Ker}(A)\), then one cannot obtain a null empirical risk because of the Gaussian CDF. The quantity
resembles a distance from a hyperplane (more details will be provided in the next section). Similar in spirit to the soft-SVM problem, the loss function (3) penalises both misclassification and close proximity to said hyperplane.
Remark 3.6
If \(\omega \in \operatorname{Ker}(A)\), then \(\langle y, \omega \rangle = \langle \nu _{x,u}, \omega \rangle \). We are then in a non-stochastic regime where full accuracy on the training set can be achieved if the averages \(\nu _{x_{i},u}\) are separable, since then
In this regime, only misclassification is penalised.
3.3 Main result
Classically, quantitative guarantees for the minimisation of the estimation error within a chosen hypothesis class (agnostic PAC-learnability) is obtained by first showing that the hypothesis set satisfies the uniform convergence property (cf. [36]), i.e. by obtaining probabilistic bounds for the worst-in-class difference between the generalisation error and the empirical error
In turn, a way to achieve this is through controlling the Rademacher complexity (or the growth function or the VC dimension) of the hypothesis class. Given a state space \(\mathcal{Z}\), a sample \(Z=\{z_{i}\}_{i=1}^{m}\) of points in \(\mathcal{Z}\) and a class \(\mathcal{G}\) of real-valued maps defined on \(\mathcal{Z}\), the (empirical) Rademacher complexity of \(\mathcal{G}\) with respect to the sample Z is defined by (cf. [32])
where the \(\varepsilon _{i}\)s are independent Rademacher (i.e. symmetric Bernoulli) random variables and \(\varepsilon =(\varepsilon _{1},\ldots , \varepsilon _{m})\).Footnote 1 The Rademacher complexity can be seen as a measure of the richness of the class of functions \(\mathcal{G}\) and its ability to provide a variety of labels \(\{g(z_{i})\}_{i=1}^{m}\) for the sample S. If we assume that the sample Z is drawn in an i.i.d. manner according to a distribution \(\mathcal{D}\), we obtain the following concentration inequality:
Theorem 3.7
Let \(\mathcal{G}\) be a family of real-valued maps defined over a sample space \(\mathcal{Z}\) with values in the interval \([0,1]\). Let \(\mathcal{D}\) be a distribution over \(\mathcal{Z}\) and \(Z=\{z_{i}\}_{i=1}^{m}\sim \mathcal{D}^{m}\) be a random sample. Denote by z a random variable distributed according to \(\mathcal{D}\). Let \(\delta >0\). Then, the following holds with probability at least \(1-\delta \)
We will estimate the Rademacher complexity in our setting then apply the above theorem to quantify the error in estimating the true risk by its empirical counterpart. This will yield our main theoretical result below. For matrices, \(\|\cdot \|\) denotes the spectral norm.
Theorem 3.8
Let Θ and Λ be two positive real numbers. We consider the family of hypotheses given by
Let \(\delta >0\), \(R>0\) and \(m\in \mathbb{N}^{*}\). We assume that the input signals lie almost surely in the \(L^{2}\)-ball of radius R
and that the covariance matrix A is positive-definite. We denote by \(\lambda _{\min }(A)\) its smallest eigenvalue. Let \(\mathcal{D}\) be a distribution over \(\mathcal{B}_{R}\times \{-1,1\}\) and \((X,V)=\{(x_{i},v_{i})\}_{i=1}^{m}\sim \mathcal{D}^{m}\) be a random sample. Then, with probability at least \(1-\delta \)
Proof
By applying Theorem 3.7 for the set of functions
together with the formula obtained in Proposition 3.4 (using the assumption on A being positive-definite), we obtain that the following holds with probability at least \(1-\delta \),
with the supremum taken over the set
As Φ is Lipschitz with constant \(\frac{1}{\sqrt{2\pi }}\), by Talagrand’s inequality [25, 32]
where we used the fact that \((\varepsilon _{i})\sim (\varepsilon _{i} v_{i})\) in the last line. On the one hand,
and on the other hand,
Recall that
We now use the following inequality for matrix-valued maps \(f:[0,T]\rightarrow \mathbb{R}^{n\times n}\) and \(g:[0,T]\rightarrow \mathbb{R}^{n}\)
together with the linearity of u and \(\|u\| \leq \Lambda \), ensuring \(\Vert \sum_{1}^{m} \varepsilon _{i}u(x_{i}(s)) \Vert \leq \Lambda \Vert \sum_{1}^{m} \varepsilon _{i} x_{i}(s) \Vert \), to obtain
Using Jensen’s and Fubini’s inequalities, we obtain the bound
Using the fact that the input paths live in the set \(\mathcal{B}_{R}\), we conclude that:
which gives the desired inequality. □
Remark 3.9
The use of the Rademacher complexity allows us to obtain a generalisation error bound that decays as \(\frac{1}{\sqrt{m}}\), which is the common rate of decay encountered in the classical supervised learning framework (with i.i.d. entries). This comes, however, at the cost of the technical assumption of the inputs being uniformly bounded in the \(L^{2}\)-norm (which is arguably a realistic assumption). Similarly to the error bounds for the SVM algorithm, it may be possible to relax this assumption at the cost of a much slower rate of decay by using the notion of VC dimension. For example, given m labelled points \((X,V)=\{(x_{i},v_{i})\}_{i=1}^{m}\) in \(\mathbb{R}^{n}\), one obtains with probability at least \(1-\delta \) for all hyperplane classifiers (cf. [32])
In the discrete case, such bounds on the VC dimension of RNNs (as a function of the number of weights in the network and the length of the sequence—which would correspond here to the number of steps one uses to discretise an input path) have been obtained, for example, by Koiran and Sontag in [22].
The previous theorem allows us to quantitatively control the estimation error:
Corollary 3.10
Let Θ, Λ and R be positive real numbers. We assume that the input signals lie almost surely in the \(L^{2}\)-ball of radius R and that the covariance matrix A is definite. Then, the class \(\mathcal{H}_{\Theta , \Lambda }\) is agnostically PAC learnable through its empirical risk-minimiser hypothesis \(H^{\mathrm{ERM}}\) (defined in (2)), i.e. there exists a function \(\tilde{m}: (0,1)^{2}\to \mathbb{N}\) such that for all \(\varepsilon ,\delta \in (0,1)\), for every distribution \(\mathcal{D}\) over \(\mathcal{X}\times \{-1,1\}\) and every sample \((X,V)\sim \mathcal{D}^{m}\) of size \(m\geq \tilde{m}(\varepsilon ,\delta )\), we have with probability at least \(1-\delta \)
More explicitly, one may take \(\tilde{m}(\varepsilon ,\delta )\) to be an integer m (ideally the smallest one) such that
Proof
Let \(\varepsilon ,\delta \in (0,1)\). Let \(\tilde{m}(\varepsilon ,\delta )\) be the smallest integer m such that
Let \(\mathcal{D}\) be a distribution over \(\mathcal{X}\times \{-1,1\}\) and \((X,V)=\{(x_{i},v_{i})\}_{i=1}^{m}\sim \mathcal{D}^{m}\) be a random sample of size \(m\geq \tilde{m}(\varepsilon ,\delta )\). Note that if
then for any hypothesis \(H \in \mathcal{H}_{\Theta , \Lambda }\)
Hence, \(R(H^{\mathrm{ERM}})\leq \inf_{H\in \mathcal{H}_{\Theta , \Lambda }} R(H)+ \varepsilon \) and
Finally, note that by Theorem 3.8 and the definition of \(\tilde{m}(\varepsilon ,\delta )\) we have
This completes the proof. □
Remark 3.11
Corollary 3.10 shows an additional major advantage of the bound obtained in Theorem 3.8: it (quantitatively) guarantees that the empirical risk minimiser is the best-in-class hypothesis with high probability. The bounds discussed, for example, in Remark 3.9 aim to directly lower the risk by choosing parameters for the hypothesis that minimises the upper bound of the risk (the right-hand side term in (4)). The efficiency of such a technique is thus very dependent on said bound being tight.
4 A study of the empirical risk
In this section, we aim to provide a better understanding of the empirical risk (in view of our future work on the non-linear case). We recall that in the pure robust stochastic case (i.e. where the covariance matrix A is positive-definite) and given a sample \((X,V)=\{(x_{i},v_{i})\}_{i=1}^{m}\), the empirical risk of an hypothesis \(H_{u,\omega ,b}\) is given by the formula
In the subsequent subsections, we will compare and draw parallels between the empirical risk minimisation (ERM) and the support vector machine (SVM) approaches and show that stochastic (linear) RNNs keep a “partial signature” of the input path as a summary of the information about the path.
4.1 An interpretation via margins
By making the change of variable \(\alpha =A^{1/2}\omega \), one can rewrite
Note that the absolute value of the quantity above is the distance of the “transformed mean” \(A^{-1/2}\nu _{x,u}\) from the hyperplane \(H(\alpha ,b)\). Given such a hyperplane, let \(I_{0}\) be the set of indices of input paths whose transformed means are correctly classified and \(m_{0}:=|I_{0}|\) be its cardinal. Define the corresponding margin \(\rho _{0}\) as the distance between the hyperplane \(H(\alpha ,b)\) and the closest correctly classified transformed average \(A^{-1/2}\nu _{x_{i},u}\),
Then, for all \(i\in I_{0}\), one has
Similarly, let \(I_{1}\) be the complement of \(I_{0}\) and \(\rho _{1}\) the distance of the furthest misclassified average \(A^{-1/2}\nu _{x_{i},u}\) from the hyperplane \(H(\alpha ,b)\)
Then, for all \(i\in I_{1}\), one has
Using these inequalities, one can bound the empirical risk as follows:
Intuitively, decreasing the upper bound above requires a balance between, on the one hand, correctly classifying the averages \(A^{-1/2}\nu _{x_{i},u}\) with a large margin \(\rho _{0}\) and, on the other hand, misclassifying as few averages as possible with the smallest worst “misclassification margin” \(\rho _{1}\). This is reminiscent of the soft SVM algorithm (see for example [7, 32]), which is the approach adopted in [33] to classify the data according to the statistics of their classes. Let us recall that the soft SVM algorithm consists of solving the following (constrained convex) optimisation problem (the parameter \(\lambda \geq 0\) is to be freely chosen depending on the desired properties of the final classifier)
Classically, this is equivalent to the dual (quadratic) problem
Given its minimiser \(\theta ^{*}\), the solution of the primal SVM problem (5) can be computed as the direction \(\alpha = \sum_{i\leq m}{\theta }^{*}_{i}v_{i}A^{-1/2}\nu _{x_{i},u}\) and, given \(i \in [\!\![1,m]\!\!]\) such that \(0< {\theta }^{*}_{i}< \lambda \), \(b=v_{i} - \langle \alpha , A^{-1/2}\nu _{x_{i},u} \rangle \).
First, note that this optimisation problem is no longer convex if we include the optimisation over the pre-processing map u. Secondly, while the solutions (for a fixed u) of the ERM and soft SVM may be similar in some generic situations, there are some significant differences in behaviour and interpretation in the results of the two algorithms:Footnote 2
-
The solution to the ERM algorithm is sensitive to the number of inputs in each class (thus, in some way, “learning” the data-generating distribution) while that of the SVM only depends on the support vectors (Fig. 2).
Figure 2 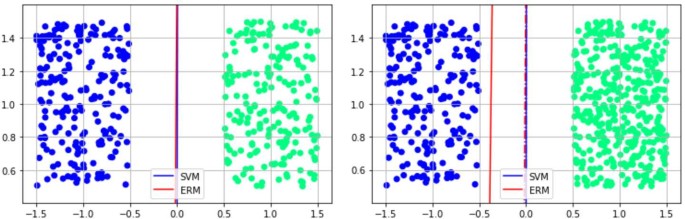
ERM (obtained via a gradient-descent algorithm) and SVM may produce similar results in generic situations (left). However, ERM is more sensitive to the relative number of inputs in each class (right). Dotted lines on the right plot recall the position of the classifiers from the left plot
-
Another key difference between these two algorithms lies in their respective objectives: the ERM attempts to find a hyperplane where most of the data is (correctly classified and) far away from said hyperplane, while the soft SVM attempts the same but only with respect to the support vectors. The results of these procedures can lead sometimes to very different outputs (Fig. 3).
Figure 3 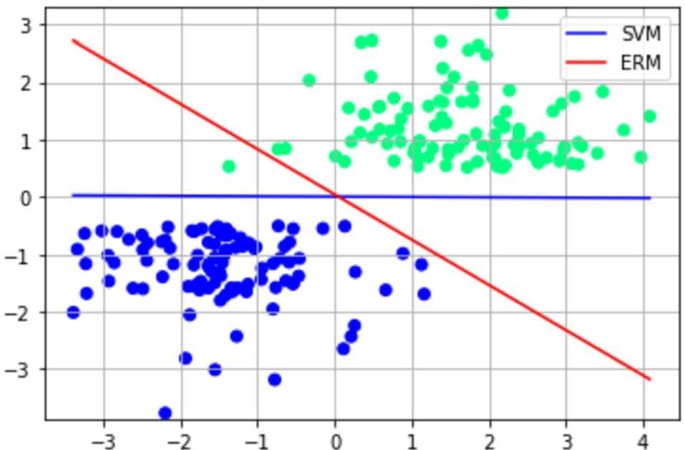
ERM and SVM seek two different geometric objectives that may result in very different outputs
-
The two algorithms have different sensitivities to outliers and mislabelled training data (which we will discuss in the next subsection).
-
Given the preprocessing map u, if one denotes the hyperplane parameters returned by the SVM algorithm by \((\omega _{u},b_{u})\), then the smoothness of the map \(u\mapsto (\omega _{u},b_{u})\) (and therefore that of \(u\mapsto \widehat{R}_{(X,V)}(H_{u,\omega _{u},b_{u}})\)) is much less trivial to prove or even define, thus rendering the use of classical gradient-descent algorithms to optimise over u unjustified (indeed, attempting to do so in several numerical experiments, the algorithm failed to converge).


Remark 4.1
In [33], the SVM algorithm is successfully used to separate classes that can be separated by their statistics (for example, the realisations of two Gaussian processes). A “good” pre-processing map u (based on a mathematical formula) is chosen beforehand; thus avoiding the use of gradient descent to optimise over this parameter.
4.2 Robustness and further analysis of the ERM
Making again the change of variable \(\alpha =A^{1/2}\omega \), we saw from the above that, informally, an ERM algorithm has the task to find parameters \((u,\omega , b)\) such that all the transformed averages \(A^{-1/2}\nu _{x_{i},u}\) are correctly classified, i.e.
and as distant from the hyperplane \(H(\alpha , b)\) as possible (thus prompting \(\Phi (-v\cdot \frac{ \langle \nu _{x,u}, \omega \rangle +b}{\sqrt{\omega ^{\top }A \omega }} )\) to be as small as possible) while working under the constraint that the overall sum of the losses associated to each training input (i.e. the empirical risk) has to be as small as possible. The combination of the latter with the loss function involving the Gaussian CDF is why this ERM algorithm differs from a simple classification of the transformed averages \(A^{-1/2}\nu _{x_{i},u}\). For example, if we assume that the two clouds
are concentrated and well separated and then introduce an additional training input \(x_{*}\) with label \(v_{*}=1\) but such that \(A^{-1/2}\nu _{x_{*},u}\) is much closer to \(C_{-}\) than to \(C_{+}\), it is then very possible for the ERM to choose to misclassify \(x_{*}\) rather than to correctly classify it (doing the latter might mean an increase in the empirical risk as the cloud \(C_{-}\) moves much closer to the new hyperplane \(H(\alpha , b)\).) In practice, the label \(v_{*}\) given to the path \(x_{*}\) could be a wrong one (i.e. mislabelled training data). However, this does not necessarily alter the result of this ERM algorithm in a drastic way (which would be the case for the hard SVM algorithm or a soft SVM algorithm with a poor choice of the regularising parameter λ). Figure 4Footnote 3 shows the dependence of the ERM and the SVM algorithms on mislabelled data.

The resulting hyperplanes obtained by ERM and SVM by introducing mislabelled training data (the dotted lines represent the hyperplanes obtained in the first experiment)
We analyse now the bounds \(\|u\|\leq \Lambda \) and \(|b|\leq \Theta \) in Theorem 3.8. While these were necessary to obtain the bounds in said theorem, they are also necessary for the ERM to converge in general. Let us first start with the bound \(\|u\|\leq \Lambda \). As far as the separation of the means \(\nu _{x_{i},u}\) of the processed inputs is concerned, \(\frac{u}{\|u\|} \) is responsible for geometrically separating these means as well as possible, while \(\|u\|\) is an amplifying factor that could be exploited for adjusting to noise and randomness in the evaluation maps once a perfect separation is achieved. For example, if \((u,\omega , b)\) are parameters of the algorithm such that all the averages \(\nu _{x_{i},u}\) are correctly classified in the sense that
then
In other words, once a training algorithm finds a pre-processing map u that enables a correct hyperplane separation of (the weighted means \(\nu _{x,u}\) of) the data, it will tend to linearly scale the norm of u to infinity with two consequences: first, further distancing the means \(\nu _{x_{i},u}\) (or more precisely \(A^{-1/2}\nu _{x_{i},u}\), as seen earlier) from the classifying hyperplane and second, distancing these averages among themselves so that, with high probability, the random vectors \(y(T,x_{i})\)s take their values in similar non-intersecting elliptic domains (becoming larger with α) centred at the \(\nu _{x_{i},u}\)s (since the Gaussian random vectors \(y(T,x_{i})\)s have the same covariance matrix A). Hence, if there are no bounds on the norm of u and if perfect classification is possible, the (non-converging) algorithm will try to transition from a robust classification to an accurate one (more details below). The bound \(|b|\leq \Theta \) prevents in some particular scenarios the choice of hyperplanes whose distance from the origin tends to infinity. If we take, for example, the case where all the data belong to the same class (less extreme examples can also be stated), say “+1”, and if \((u,\omega , b_{0})\) are parameters of the algorithm such that all the averages \(\nu _{x_{i},u}\) are correctly classified, then
Note also that the bounds on the norm of u (and b) are interchangeable with a rescaling of the covariance matrix A as the classifier with parameters \(({\alpha u,\omega ,\alpha b})\) and covariance matrix A generates the same risk as the classifier with parameters \(({ u,\omega , b})\) and covariance matrix \(A/\alpha ^{2}\). Hence, we choose the bound \(\Lambda =1\) in the numerical experiments and control the covariance matrix through a noise scale to be chosen carefully (see Sect. 5).
Finally, we discuss the condition of definiteness of the covariance matrix A and its role in the robustness of the classification algorithm. When A is positive-definite, we have seen that the goal of the ERM is solving the minimisation problem
On the one hand, if the empirical risk is interpreted as a measure of the precision of the classification task on the training set, then we see that in this regime (A positive-definite), a full precision (null risk) is not achievable (due to the randomness of the evaluation map). The same applies to the classification of the data on a validation set as the label is a random variable whose value will depend on the current simulation (of the Brownian motion and the solution to the S.D.E). On the other hand, and as we have previously seen, note that even for a fixed pre-processing map u, it is clear that the choice of the optimal parameters depends explicitly on all the training data, providing in this way a robustness against mislabelled data in the training set. For these reasons, and the ones detailed above, we call this the robust or the stochastic regime.
If we now take \(A=0\), the objective of an ERM becomes the solution of the minimisation problem
The task at hand is a mere classification of the averages \(\nu _{x_{i},u}\) of the processed data. If there exists a pre-processing map u such that these averages are separable, then an ERM algorithm will achieve a full precision on the training data set (and in general, a unique solution does not exist unless we introduce an additional constraint like maximising the margin of the classifying hyperplane, as in SVM). However, this classification will generally depend only on some support vectors \(\nu _{x_{i},u}\) (i.e. the closest averages to the classifying hyperplane) while ignoring the information provided by the rest of the training data, hence potentially becoming sensitive and vulnerable to mislabelling and the data-generating distribution. We call such a regime the accurate regime.
In the general case (A not positive-definite but not necessarily null), the ERM may choose either the robust or the accurate regime depending on how well the data can be separated. If the averages \(\nu _{x_{i},u}\) are separable, the accurate regime is preferred as it leads to a null empirical risk, otherwise the ERM may choose a robust solution. We refer, for example, to [11, 35, 38] for more information on the general topic of the trade-off between accuracy and robustness.
4.3 Information retained by stochastic RNNs
In this subsection, we highlight that the ERM is equivalent to a minimisation of a functional of the signatures of the augmented input paths \((t,\int x_{t}\,\mathrm{d}t)_{t\leq T}\). We recall that the signature \(S(z)=(Z^{n})_{n\in \mathbb{N}}\) of a path z defined over an interval \([0,T]\) with values in a Banach space E is the sequence of its iterated integrals, i.e. for all \(s\leq t\),
The role of the signature in RNNs should not come as a surprise for two main reasons:
-
The signature of a path is the only information needed from a path to solve a differential equation. This is the cornerstone of the theory of rough paths (cf. [29, 30]).
-
Every path is uniquely characterised (up to what is called a tree-like equivalence) by its signature [18]. This fact is the basis for much research in the machine learning of data streams. These streams are mapped via their (truncated) signatures to vectors in the tensor algebra, thus allowing one to use many of the classical machine-learning techniques (such as feed-forward neural networks) for data streams (e.g. [15, 21, 26]).
For more information, we refer the reader to the original work of Chen [5], the modern formulation in [30] and the introduction to signature methods in machine learning in [6].
We now reformulate the ERM problem in a way that fully separates the tunable parameters of the network from the information provided by the paths in the training dataset.
Theorem 4.2
Define \(\mathbb{H}\) as the Hilbert space
with inner product given by
Then, the ERM is equivalent to the following optimisation problem
where \(\mathcal{C}_{A}\) is defined as
Proof
We write the problem at hand
in the simpler equivalent form
Note now that we can expand the mean \(\nu _{x,u}\) into a series
so that one can separate, in the inner product \(\langle \alpha , \nu _{x,u} \rangle +\beta \), the tunable parameters from a functional of the input signals
This concludes the proof. □
Remark 4.3
Note that
where \(X_{\boldsymbol{\cdot }}:=\int _{0}^{\boldsymbol{\cdot }} x(s) \,\mathrm{d}s\) denotes a primitive of x. Hence, the sequence \((\int _{0}^{T} \frac{(T-s)^{k}}{k!}x(s)\,\mathrm{d}s )_{k \geq 0}\) can be obtained from the signature of the path \((t,X_{t})_{t\leq T}\).
Theorem 4.2 highlights the information retained by a stochastic RNN (with architecture and loss function chosen as described in this paper). More explicitly, we have the following theorem.
Theorem 4.4
Both during training (solving the ERM problem) and classification (generating labels for unseen data), the continuous-time stochastic RNN (with linear activation function) is uniquely determined by the partial signature Ŝ of the input path defined by
Proof
We have already shown in Theorem 4.2 that the ERM problem can be written as a minimisation problem of a functional of the partial signatures of the training paths (and that no other information about said paths is required). If we denote by \((u,\omega ,b)\) some possible parameters of an ERM classifier \(H^{\mathrm{ERM}}\) and given an input path x, then the RNN generates the label \(v=\operatorname{sign}( \langle y_{u}(T,x), \omega \rangle +b)\) with \(y_{u}(T,x)\sim \mathcal{N} (\nu _{x,u}, A )\). Following the proof of Theorem 4.2, \(\nu _{x,u}\) can also be expressed as a functional of \(\widehat{S}(x)\) only
This completes the proof of the claims. □
We believe that a similar result to Theorem 4.4 holds for generic RNNs, i.e. that continuous-time RNNs (even with non-linear activation functions) can be viewed as kernel machines involving the (full) signatures of the input paths. We refer, for example, to [28] (and the references therein) for the first results in this direction.
Even though the RNN uses only the partial signature (7) of the time-lifted input paths (instead of the full signature), it turns out that it is still a faithful representation of continuous paths.
Theorem 4.5
The partial signature map Ŝ defined over the space of continuous paths defined over an interval \([0,T]\) and with values in a finite-dimensional space is injective.
Proof
Without loss of generality, we will consider the case of real-valued paths. By a simple change of variable and a reparametrisation of the path, it is equivalent to show that the map
is injective. As S̃ is linear it is also equivalent to show that \(\widetilde{S}(x)=0\) if and only if \(x=0\). Let then x be a continuous real-valued path such that \(\widetilde{S}(x)=0\). Then, for every polynomial function P, one has \(\int _{0}^{T} P(s)x(s)\,\mathrm{d}s=0\). Let \(\varepsilon >0\) be arbitrary and let P be a polynomial function such that \(\|x-P\|_{\infty ,[0,T]}\leq \varepsilon \). Then, one has
Therefore, \(\int _{0}^{T} x^{2}(s)\,\mathrm{d}s=0\), from which we conclude that indeed \(x=0\). □
Remark 4.6
Despite the partial signature transform being injective, it is still possible for the linear RNN not to be able to distinguish two paths x and x̃ if the inner product of their partial signatures with the matrices \(({W_{0}^{k}}u )_{k\geq 0}\) are the same, i.e.
Replacing the sequence \(({W_{0}^{k}}u )_{k\geq 0}\) by another whose entries can be independent is the cornerstone and the reason behind the power of signature techniques. However, these techniques are confronted with computational issues and therefore the signature has to be restricted to low orders. RNNs are able, however, to surmount this obstacle by increasing the dimension n and thus allowing for more degrees of freedom (while signatures are computed implicitly, as shown above through the recursive architecture).
Using the factorial decay of the elements of the partial signature sequence (which is trivial and explicit in our case), we can then obtain a good approximation for the ERM by truncating the signature. To show such a result, we first prove the following technical lemma.
Lemma 4.7
Let \(N\in \mathbb{N}^{*}\), \(u\in \mathbb{R}^{n\times r}\), \(\omega \in \mathbb{R}^{n}\) and \(x\in L^{1} ([0,T],(\mathbb{R}^{r},\|\cdot \|_{2}) )\). Then,
Proof
Expanding the difference that we want to bound we obtain
For every \(k\in \mathbb{N}\), one trivially has
while for every \(a\geq 0\)
The combination of the three arguments above then gives the desired result. □
We can now show how one may exploit the signature-based expansion of the empirical risk in order to obtain an approximate solution to the ERM.
Theorem 4.8
Let Θ, Λ and R be positive real numbers and \(N\in \mathbb{N}^{*}\). We consider the set of parameters
Assume that all input paths take their values in the \(L^{1}\)-ball of radius R
Given a sample \((X,V)=\{(x_{i},v_{i})\}_{i=1}^{m}\), let \((u_{0},\omega _{0},b_{0})\) be a solution to the ERM problem
and \((\bar{u},\bar{\omega },\bar{b})\) be a solution to the “truncated” ERM problem
Then,
Proof
For lighter expressions, we will introduce the following notation
The inequality \(\widehat{R}_{(X,V)}(H_{u_{0},\omega _{0},b_{0}}) \leq \widehat{R}_{(X,V)}( \bar{u},\bar{\omega },\bar{b})\) is a direct consequence of the definition of \((u_{0},\omega _{0},b_{0})\). We decompose the difference of these two terms in the following way
By the definition of \((\bar{u},\bar{\omega },\bar{b})\), the second difference is non-positive,
Let \((u,\omega ,b) \in \mathcal{P}_{\Theta , \Lambda }\). As Φ is \(\frac{1}{\sqrt{2\pi }}\)-Lipschitz, we have
For each \(i\in [\!\![1,m]\!\!]\), the following holds by Lemma 4.7 and the assumptions on the parameters ω and u and the path \(x_{i}\)
The result is then directly obtained by applying the above bounds to the vectors \((\bar{u},\bar{\omega },\bar{b})\) and \((u_{0},\omega _{0},b_{0})\). □
Theorem 4.8 demonstrates then the possible power of the application of the signature-based decomposition of the empirical risk. In our setting, this technique avoids, for example, the expensive computation of \(\nu _{x,u}\) (as integrals of time-dependent matrix exponentials) for each path in the training set and replaces it with the computation and storage of the powers \((W_{0}^{k})_{k\leq N}\). However, in this still simple setting, we will not base our optimisation techniques on this method and will reserve its application for the non-linear case where exact formulae are not available.
5 Numerical results
In this subsection, we present the results of some numerical experiments run on real and synthetic data. The focus will be on the effect of noise on the accuracy and the robustness of the RNN and on the verification of the theoretical bound obtained in Theorem 3.8.
The application to real-world data will be demonstrated on the Japanese Vowels dataset.Footnote 4 This dataset contains speech recordings of nine male subjects pronouncing a combination of Japanese vowels. The recordings are in the form of 12-dimensional (\(r=12\)) discrete time series with varying lengths. To create a binary classification problem of continuous-time paths, we restrict ourselves to the recordings of the first two subjects and we reparametrise the time series to the unit interval.
For the synthetic data, we consider 5-dimensional trigonometric polynomials (\(r=5\))
defined over the interval \([0,2\pi ]\). Here, we take \(N=6\) and the parameters \(a_{k}\) and \(b_{k}\) are chosen (uniformly randomly) in the intervals \(I^{r}\) and \(J^{r}\), respectively, where, for one class \(I = [-0.2, 1]\) and \(J = [-1, 0.2]\) and for the other \(I = [-1, 0.2]\) and \(J = [-0.2, 1]\). We generate 70 samples for each class for our dataset.
We take the dimension of the network to be \(n=50\) (and the dimension d of the Brownian motion is taken to be equal to n). This is quite large for our simple synthetic dataset and appropriate for the Japanese Vowels dataset but still small compared to typical reservoirs, where n can be larger than 500 to make the reservoir self-averaging. The entries of the connectivity matrix W are drawn from independent Gaussian distributions \(\mathcal{N}(0, \frac{0.9}{\sqrt{n}})\) (the choice of the value 0.9 is to insure the numerical stability of the system). To generate the noise matrix Σ, we first draw positive values \(\lambda _{1},\ldots , \lambda _{n}\) uniformly over \((0,1)\), then uniformly a random orthogonal matrix U to output the matrix
The parameter δ is a noise scale that has to be chosen carefully. A large value for δ makes the noise dominant and the RNN unable to reach an acceptable accuracy, while too small a value makes the system less robust.
The ERM problem will be solved numerically using a gradient-descent (GD) algorithm. Recall that, given a training sample \((X,V)=\{(x_{i},v_{i})\}_{i=1}^{m}\), we aim to minimise the quantity
as a function of the parameters u, ω and b. As discussed in Sect. 4.2, we impose the bound \(\|u\|\leq 1\). To achieve a superior classification performance, we do not impose an a priori bound on b. Let us first say a few words about some simplifications in the implementation of the gradient-descent (GD) algorithm in this simple linear case. If we consider the loss function associated with a single observation \((x,v)\) as a function of u, ω and b
then we may explicitly compute the gradient of L (for \(i\in [\!\![1,n]\!\!]\) and \(j\in [\!\![1,r]\!\!]\))
where \(e_{i,j}\) stands for the canonical \(n\times r\) basis matrix \((\delta _{ik}\delta _{jl} )_{k\leq n, l\leq r}\) and \(z_{i}\) stands for the ith coordinate of the vector z. Apart from its simple expression, one can see that the averages \((\nu _{x,e_{i,j}})_{i\leq n, j\leq r}\) need to be computed for each example x in the training set in order to run the algorithm. One can then exploit these to compute the mean \(\nu _{x,u}\) at each iteration of the algorithm as a linear combination of the means \((\nu _{x,e_{i,j}})_{i\leq n, j\leq r}\) instead of a full new computation that can be heavy due to the presence of matrix exponentials. In our implementation, we used Scipy’s minimise function with nonlinear constraintsFootnote 5 that is a gradient-descent algorithm with suitably adjusted step sizes (based on the Sequential Least Squares Programming algorithm detailed in [24]). Due to the non-convexity of the problem, the algorithm is run a few times (typically 5 times) with random initialisations of the parameters in order to avoid poor local minima. The solution with the smallest loss function is then chosen.
The experiments consist of three parts:
-
(1)
First, we check the accuracy achieved on a fixed-size testing set (30% of the total available data) while increasing the size of the training set. Recall that the computed accuracies are random realisations depending on the results of the simulations (of the solution to the SDE (1)).
-
(2)
We verify the validity of the theoretical bound obtained in Theorem 3.8 as a function of the size of the training set. More precisely, having computed some values for the parameters u, ω and b, and thus the corresponding hypothesis H, we compare the difference \(\vert R(H)-\widehat{R}_{(X,V)}(H) \vert \) with the theoretical bound (which is valid with high probability)
$$ \frac{4}{\sqrt{2\pi m \lambda _{\min }(A)}} \biggl(\Theta + R \biggl( \int _{0}^{t} \bigl\Vert e^{W_{0}(t-s)} \bigr\Vert ^{2}\,\mathrm{d}s \biggr)^{1/2} \biggr) + \frac{2+5\sqrt{\log (2/\delta )/2}}{\sqrt{m}}. $$In the above, the true risk \(R(H)\) is computed as an empirical risk over the testing set. The value R is computed as the maximum of the \(L^{2}\)-norm of the paths in the whole dataset, while Θ is computed as the largest value obtained for \(|b|\) in the accuracy experiment detailed above. We take the value \(\delta = 0.01\) so that the bound holds with probability 0.99.
-
(3)
We verify the robustness of the learning in the following way. We train the network with a corrupt dataset where a portion of the labels of the training inputs has been changed, then compute the resulting accuracy based on the test set. This robustness test is quite simple and does not show the full potential of the architecture, but we suspect that such robustness also holds when the input paths are themselves being perturbed. For other measures of robustness, we refer the reader to the previously cited references and the additional references [1, 4, 8] that investigate the robustness of training with corrupted datasets.
We start by the experiments on the Japanese vowels dataset with three choices of noise scales \(\delta \in \{1,1.5,2.5\}\) in (8). The resulting plots are shown in Fig. 5. In the accuracy plots:
-
the solid lines show the accuracy based on classifying the averages \(\nu _{x,u}\) of the paths in the test dataset with the obtained hyperplane \(h_{\omega ,b}\). In other words, the generated label for a path x is \(v=\operatorname{sign}( \langle \nu _{x,u}, \omega \rangle +b)\). As \(\nu _{x,u}\) is the hidden state of a noiseless RNN,Footnote 6 we refer to this scenario as noiseless accuracy or NRNN.
-
The dotted lines show the accuracy of 5 simulated labels produced by the stochastic RNN. Here, the generated label for a path x is \(v=\operatorname{sign}( \langle y_{u}(T,x), \omega \rangle +b)\), where \(y_{u}(T,x)\) is simulated as \(y_{u}(T,x)\sim \mathcal{N} (\nu _{x,u}, A )\). We refer to this scenario as simulated stochastic accuracy.

Verification of the theoretical PAC-bound (Theorem 3.8) and accuracy of the network for the Japanese vowels dataset. Each row of figures represents the results for different noise scales (as defined in Equation (8)); 1, 1.5 and 2.5, respectively. The middle column shows the evolution of the accuracy of the network when increasing the size of the training dataset. The right column shows how an increasing portion (described as mislabelling frequency) of corrupt labels in the training dataset affects the accuracy on the test set. Solid lines show the accuracy of classification by a noiseless RNN (trained as a stochastic RNN). Dotted lines show the results of simulations of the realised labels by the stochastic RNN
Note that because of the discontinuity of the hyperplane classifying function, the former is not expected to be an average of the latter. For readability, we report some numerical values for 10 simulations in Table 1:
-
the first column refers to the value of the noise scale δ in (8);
-
the group of columns “Accuracy” reports the results of the experiment after training with the entire training set, while the group of columns “Robustness test accuracies” reports the accuracy of the network after training with the entire training set with 10% of mislabelled data;
-
the column NRNN gives the accuracy of classification of the averages \(\nu _{x,u}\) with the hyperplane \(h_{\omega ,b}\) (these labels are given by \(v=\operatorname{sign}( \langle \nu _{x,u}, \omega \rangle +b)\));
-
the columns “min”, “max” and “avg.” give, respectively, the smallest, the largest and the average observed accuracy over the 10 simulations (the labels are simulated as \(v\sim \operatorname{sign}( \langle \mathcal{N} (\nu _{x,u}, A ), \omega \rangle +b)\)).
As usually observed when working with PAC-bounds based on the Rademacher complexity, the theoretical bound obtained in Theorem 3.8 can be very loose. We note, however, in Fig. 5 that the difference becomes smaller with larger noise scales. In Table 1, we note an almost perfect noiseless accuracy even in the presence of noise. A striking fact, however, is that, on average and in the presence of noise, there is no marked loss in the performance of the RNN when training with some mislabelled data.
Training with synthetic data showed a higher tolerance to the noise scales. In Fig. 6, we show the results of the same experiments as before with the noise scales \(\delta \in \{2,4, 6\}\). Numerical values are reported in Table 2 (with 15% for mislabelled data in the robustness test). We observe again the validity of the theoretical PAC-bound obtained in Theorem 3.8 (with the difference becoming smaller with higher noise scales) and note the same persistence in the quality of the labels generated by the RNN when training with mislabelled data.

Verification of the theoretical PAC-bound (Theorem 3.8) and accuracy of the network for the synthetic dataset. Each row of figures represents the results for different noise scales (as defined in Equation (8)); 2, 4 and 6, respectively. The middle column shows the evolution of the accuracy of the network on increasing the size of the training dataset. The right column shows how an increasing portion (described as mislabelling frequency) of corrupt labels in the training dataset affects the accuracy on the test set. Solid lines show the accuracy of classification by a noiseless RNN (trained as a stochastic RNN). Dotted lines show the results of simulations of the realised labels by the stochastic RNN
Availability of data and materials
The datasets analysed during the current study are available in the UCI Machine Learning Repository.
Notes
We assume that the random quantity inside the expectation is indeed measurable. This happens to be the case for most machine-learning applications, including the one discussed in this paper.
In the following arguments, we show these differences for classification tasks for points in the plane. In our setting, this is equivalent to taking the dimensions \(r=n=2\), the pre-processing map \(u=\mathrm{Id}\) and the input paths as constant paths.
Here again, we illustrate our point with the classification task of planar points.
Note, however, that a noiseless RNN will train differently and consequently produce different parameters u, ω and b in general.
References
Barreno, M., Nelson, B., Sears, R., Joseph, A.D., Tygar, J.D.: Can machine learning be secure? In: Proceedings of the 2006 ACM Symposium on Information, Computer and Communications Security, pp. 16–25 (2006)
Bartlett, P.L., Boucheron, S., Lugosi, G.: Model selection and error estimation. Mach. Learn. 48(1), 85–113 (2002)
Bhattacharya, K., Hosseini, B., Kovachki, N.B., Stuart, A.M.: Model reduction and neural networks for parametric PDEs. SMAI J. Comput. Math. 7, 121–157 (2020)
Biggio, B., Nelson, B., Laskov, P.: Poisoning attacks against support vector machines (2012)
Chen, K.-T.: Integration of paths, geometric invariants and a generalized Baker–Hausdorff formula. Ann. Math. (2) 65, 163–178 (1957)
Chevyrev, I., Kormilitzin, A.: A primer on the signature method in machine learning. arXiv preprint (2016). arXiv:1603.03788
Cortes, C., Vapnik, V.: Support-vector networks. Mach. Learn. 20(3), 273–297 (1995)
Dalvi, N., Domingos, P., Sanghai, S., Verma, D.: Adversarial classification. In: Proceedings of the Tenth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, pp. 99–108 (2004)
DePasquale, B., Cueva, C.J., Rajan, K., Escola, G.S., Abbott, L.: full-FORCE: a target-based method for training recurrent networks. PLoS ONE 13(2), e0191527 (2018)
Doya, K.: Bifurcations in the learning of recurrent neural networks 3. Learn. RTRL 3, 17 (1992)
Fawzi, A., Fawzi, O., Frossard, P.: Analysis of classifiers’ robustness to adversarial perturbations. Mach. Learn. 107(3), 481–508 (2018)
Funahashi, K.-I., Nakamura, Y.: Approximation of dynamical systems by continuous time recurrent neural networks. Neural Netw. 6(6), 801–806 (1993)
Gonon, L., Grigoryeva, L., Ortega, J.-P.: Approximation bounds for random neural networks and reservoir systems. arXiv preprint (2020). arXiv:2002.05933
Gonon, L., Grigoryeva, L., Ortega, J.-P.: Risk bounds for reservoir computing. J. Mach. Learn. Res. 21, Paper No. 240, 61 pp. (2020)
Graham, B.: Sparse arrays of signatures for online character recognition. arXiv preprint (2013). arXiv:1308.0371
Gressmann, F., Király, F.J., Mateen, B., Oberhauser, H.: Probabilistic supervised learning. arXiv preprint (2018). arXiv:1801.00753
Hälvä, H., Hyvarinen, A.: Hidden Markov nonlinear ICA: unsupervised learning from nonstationary time series. In: Conference on Uncertainty in Artificial Intelligence. PMLR, pp. 939–948 (2020)
Hambly, B., Lyons, T.: Uniqueness for the signature of a path of bounded variation and the reduced path group. Ann. Math. (2) 171(1), 109–167 (2010)
Hyvarinen, A., Morioka, H.: Nonlinear ICA of temporally dependent stationary sources. In: Artificial Intelligence and Statistics. PMLR, pp. 460–469 (2017)
Jaeger, H., Haas, H.: Harnessing nonlinearity: predicting chaotic systems and saving energy in wireless communication. Science 304(5667), 78–80 (2004)
Király, F.J., Oberhauser, H.: Kernels for sequentially ordered data. J. Mach. Learn. Res. 20, Paper No. 31, 45 pp. (2019)
Koiran, P., Sontag, E.D.: Vapnik–Chervonenkis dimension of recurrent neural networks. Discrete Appl. Math. 86(1), 63–79 (1998)
Koltchinskii, V., Panchenko, D.: Rademacher processes and bounding the risk of function learning. In: High Dimensional Probability, II (Seattle, WA, 1999). Progr. Probab., vol. 47, pp. 443–457. Birkhäuser, Boston (2000)
Kraft, D., et al.: A software package for sequential quadratic programming
Ledoux, M., Talagrand, M.: Probability in Banach Spaces. Ergebnisse der Mathematik und ihrer Grenzgebiete (3), vol. 23. Springer, Berlin (1991)
Levin, D., Lyons, T., Ni, H.: Learning from the past, predicting the statistics for the future, learning an evolving system. arXiv preprint (2013). arXiv:1309.0260
Li, Z., Han, J., E, W., Li, Q.: On the curse of memory in recurrent neural networks: approximation and optimization analysis. In: International Conference on Learning Representations (2021)
Lim, S.H.: Understanding recurrent neural networks using nonequilibrium response theory. J. Mach. Learn. Res. 22, 1–48 (2021)
Lyons, T.J.: Differential equations driven by rough signals. Rev. Mat. Iberoam. 14(2), 215–310 (1998)
Lyons, T.J., Caruana, M., Lévy, T.: Differential equations driven by rough paths. In: Lectures from the 34th Summer School on Probability Theory Held in Saint-Flour, July 6–24, 2004. Lecture Notes in Mathematics, vol. 1908, pp. 6–24. Springer, Berlin (2007). With an introduction concerning the Summer School by Jean Picard
Maass, W., Joshi, P., Sontag, E.D.: Computational aspects of feedback in neural circuits. PLoS Comput. Biol. 3(1), e165 (2007)
Mohri, M., Rostamizadeh, A., Talwalkar, A.: Foundations of Machine Learning. Adaptive Computation and Machine Learning. MIT Press, Cambridge (2012)
Nestler, S., Keup, C., Dahmen, D., Gilson, M., Rauhut, H., Helias, M.: Unfolding recurrence by Green’s functions for optimized reservoir computing. In: Larochelle, H., Ranzato, M., Hadsell, R., Balcan, M.F., Lin, H. (eds.) Advances in Neural Information Processing Systems, vol. 33, pp. 17380–17390. Curran Associates, Red Hook (2020)
Oberhauser, H., Schell, A.: Nonlinear independent component analysis for continuous-time signals. arXiv preprint (2021). arXiv:2102.02876
Raghunathan, A., Xie, S.M., Yang, F., Duchi, J., Liang, P.: Understanding and mitigating the tradeoff between robustness and accuracy. arXiv preprint (2020). arXiv:2002.10716
Shalev-Shwartz, S., Ben-David, S.: Understanding Machine Learning: From Theory to Algorithms. Cambridge University Press, Cambridge (2014)
Sompolinsky, H., Crisanti, A., Sommers, H.-J.: Chaos in random neural networks. Phys. Rev. Lett. 61(3), 259–262 (1988)
Tsipras, D., Santurkar, S., Engstrom, L., Turner, A., Madry, A.: Robustness may be at odds with accuracy. In: International Conference on Learning Representations (2019)
Acknowledgements
YB, SN and HR are grateful for the financial support of the Excellence Initiative of the German federal and state governments through its grant G:(DE-82)EXS-SFneuroIC002: “Recurrence and stochasticity for neuro-inspired computation”.
Funding
The research of YB, SN and HR was supported by the Excellence Initiative of the German federal and state governments (G:(DE-82)EXS-SFneuroIC002: “Recurrence and stochasticity for neuro-inspired computation”). Open Access funding enabled and organized by Projekt DEAL.
Author information
Authors and Affiliations
Contributions
HR acquired the funding, initiated the idea of the project and helped in directing the research and inspecting the final version of the manuscript. YB proved the theoretical results of this paper, drafted the manuscript and designed the numerical experiments. WB carried out the numerical experiments of Sects. 4.1 and 4.2 and prepared the corresponding figures. SN carried out the numerical experiments of Sect. 5 and prepared the corresponding figures along with the sketch of Fig. 1. All the authors have read and agreed to the published version of the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare that they have no competing interests.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Boutaib, Y., Bartolomaeus, W., Nestler, S. et al. Path classification by stochastic linear recurrent neural networks. Adv Cont Discr Mod 2022, 13 (2022). https://doi.org/10.1186/s13662-022-03686-9
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s13662-022-03686-9